题目大意:n个同学找朋友,依次走进大操场,进去之后身高最近的是朋友,同近的高的是朋友,请问2到n号同学的朋友分别是谁?
题目描述
根据社会学研究表明,人们都喜欢找和自己身高相近的人做朋友。现在有n名身高两两不相同的同学依次走入教室,调查人员想预测每个人在走入教室的瞬间最想和已经进入教室的哪个人做朋友。当有两名同学和这名同学的身高差一样时,这名同学会更想和高的那个人做朋友。比如一名身高为1.80米的同学进入教室时,有一名身高为1.79米的同学和一名身高为1.81米的同学在教室里,那么这名身高为1.80米的同学会更想和身高为1.81米的同学做朋友。对于第一个走入教室的同学我们不做预测。
输入
第一行:一个整数n,表示有个同学依次走进教室
接下来n行,每行一个浮点数a,表示同学的身高
输出
输出n-1行,分别表示第2到n个同学的朋友的编号
样例输入
5
1.1
1.3
1.2
1.123456
1.000001
样例输出
1
2
1
1
提示
教室很大,n不超过10万,身高各不相同,精确到微米
解题思路
由于我们知道所有人的身高和走进教室的次序,所以我们可以采用离线的做法来解决这样的问题,我们用排序加链表的方式帮助每一个人找到在他之前进入教室的并且和他身高最相近的人。
首先,读入数据,注意小数有精度问题,可以转成整数再进行后续操作;接着,索引排序,将同学的编号按照身高进行排序;然后建立双向链表,这样就可以知道任何一个编号的同学的前一个是谁、后一个是谁,朋友的话,也只可能从这两个里面产生;最后离线处理,从n开始,一直到2,确定每个同学的朋友,n找完朋友后,删除n,因为n-1找朋友的时候n还不存在。得到结果后,依次输出。
程序实现
读入小数,存储小数,比较时,只有矮的比高的更接近该同学的身高,才选矮的,这里的身高差,至少1e-6,为了避免精度问题,至少近1e-7才算更接近。

转成整数,为了避免精度问题,加上一个0.1到0.9的数字,只有不足1的部分转成整数时自动去掉。
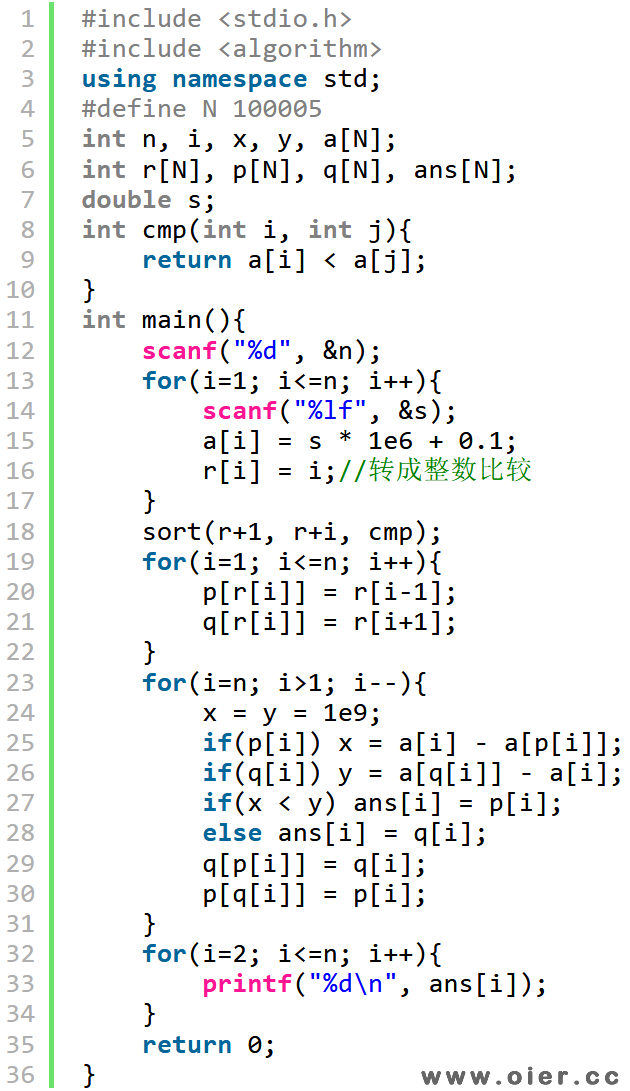
之间读入字符串,转成整数。
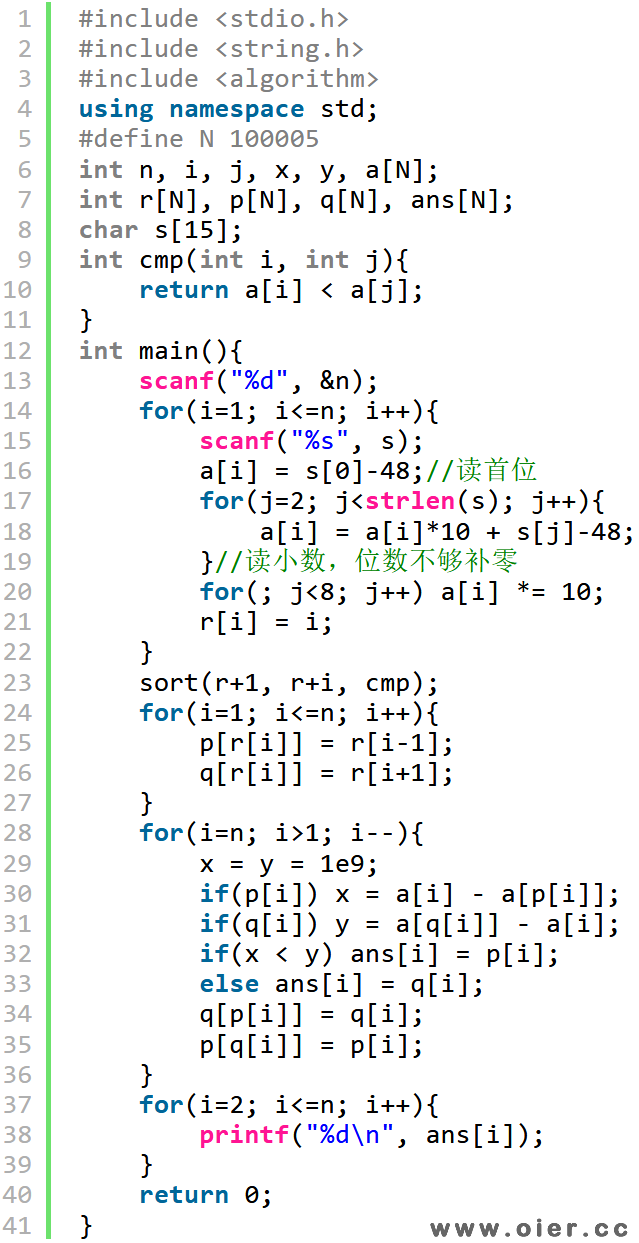
不会使用链表,可以骗分,小数据暴力枚举,大数据哈希骗分。
