题目大意:对一个长度不超过100万的字符串的所有后缀进行排序,输出每一名的编号。
题目描述
读入一个长度为 的由大小写英文字母或数字组成的字符串,请把这个字符串的所有非空后缀按字典序从小到大排序,然后按顺序输出后缀的第一个字符在原串中的位置。位置编号为 到 。
输入输出格式
输入格式:
一行一个长度为 的仅包含大小写英文字母或数字的字符串。
输出格式:
一行,共n个整数,表示答案。
输入输出样例
输入样例#1:
ababa
输出样例#1:
5 3 1 4 2
说明
解题思路
使用STL进行索引排序:将每一个后缀串的编号放入p数组,然后对编号进行排序,比较规则就是以该编号为开头、一直到结尾的字符串的大小。效率取决于字符串的重复多不多,重复多的话就会超时,如果是随机串的话,时间复杂度是O(nlogn)。
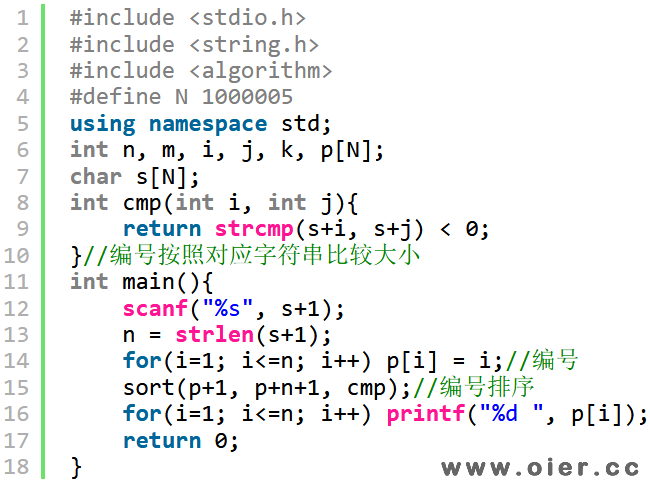
倍增+基数排序:时间复杂度是O(nlogn),常数比较大,需要的额外空间也比较多,相比STL代码复杂了很多。
为避免混淆特此声明:第i个字符串、i串等,都是表示以s[i]开头的字符串(后缀串),排名为i的字符串会注明“排名”、“排”等字眼。
首先是数组定义:p即后缀数组,p[i]记录排在第i名的字符串的位置;q是临时的后缀数组;r是排名数组,r[i]表示第i个字符串的排名;t是统计数组,t[i]表示i出现了多少次;x是第一关键字数组、y是第二关键字数组,因为我们采用的是倍增思想,第一次(预处理)可以得到每个字符的排名(后缀串首字母排名),第二次可以得到任意两个相邻字符的排名(最后一个与空字符相邻,后缀串前2个字母的排名),第三次可以得到任意4个相邻字母的排名(后面不足4个与空字符相邻、后缀串前4个字母)……如何由2个2个推出4个4个?靠的就是第一关键字x(前一半)和第二关键字y(后一半)。
1、预处理首字母排名,代码2的11到15行,将各个后缀串的首字母排名保存到r[i]。
2、倍增的基数排序,x和y的间隔是c,串每次翻倍
(1)计算x数组和y数组(代码17-21行),后面根据这两个关键字进行排序
(2)对y[i]进行桶排序(代码23-到26行):首先统计各个关键字(1到n)的出现次数,接着计算前缀和,目的是确定关键字y[i]放在区间( t[i-1], t[i] ],最后将关键字依次放到临时的后缀数组q,此时q[i]表示排名为ii的串的编号。(i串的关键字是y[i],y[i]的排名是t[ y[i] ],排在第t[ y[i] ]位的就是i串,所以q[ t[ y[i] ] ] = i)
(3)同理,继续对x[i]进行通排序(代码28到31行),需要注意的是,x[i]相同时,按照y[i]进行排序。因此,第2次排序的不是原来的编号i,而是按照第二关键字排好的q[i]。
最后依次放入后缀数组p,循环变量必须倒序,这样才能保证x相同y大的排在后面,因为q[i]是排在i位的,排在后面的就应该放在p数组的较后面。为了避免复制粘贴等行为出错,建议将第一次桶排也写成倒序形式。
(4)计算i串排名r[i](代码34-39行):根据r即使p,得到p后再重新更新r,这样才能循环下去求解出最终的p。首先r[ p[i] ] = i,因为排在第i位的串的排名就是i。然后,需要考虑相同的情况,因为串相同而排名不同,会影响到后面的排名,故需要加上判断是否与前一个相同,相同则排名相同。
排序的结果就是,最终p[i]各不相同,因为没有一个后缀串是相同的。
程序实现
